单GPU运行数千大模型 UC伯克利提出全新微调方法S-LoRA,革新数据处理与存储范式
大型语言模型(LLM)的兴起推动了人工智能领域的飞速发展,但随之而来的巨大计算与存储成本,使得模型的微调与部署成为一项极具挑战性的任务。传统上,为每个任务或用户定制一个独立的大模型需要消耗海量的GPU内存和存储空间,这严重限制了其在实际场景中的规模化应用。加州大学伯克利分校的研究团队提出了一种革命性的微调方法——S-LoRA(Scalable Low-Rank Adaptation),它能够在单个GPU上同时运行和管理数千个经过微调的大型语言模型,为AI模型的个性化与高效部署开辟了全新路径。
一、 背景:大模型微调的效率瓶颈
大模型微调通常采用参数高效微调技术,其中LoRA(Low-Rank Adaptation)因其高效性而广受欢迎。LoRA通过在原始模型参数旁添加低秩适配器模块来学习特定任务的知识,而无需更新整个庞大的模型参数。当需要服务于大量不同任务或用户时(例如,为成千上万的企业或开发者提供定制化模型),即使每个适配器很小,同时加载和管理成千上万个这样的适配器也会导致GPU内存爆炸性增长,引发严重的显存瓶颈和计算调度难题。
二、 S-LoRA的核心创新:可扩展的低秩适配
UC伯克利团队提出的S-LoRA,正是为了解决这一规模化部署的挑战。其核心思想在于,通过一系列系统级和算法级的协同优化,实现对大量LoRA适配器的高效、统一管理。
- 统一内存管理与动态调度:S-LoRA设计了一个统一的内存池,用于存储所有LoRA适配器的权重。它采用了一种创新的动态加载与卸载机制,能够根据实时请求,智能地将活跃任务所需的适配器权重快速调入GPU显存,而将非活跃的权重换出至CPU内存或高速存储。这种类似于操作系统虚拟内存管理的方法,极大地缓解了显存压力。
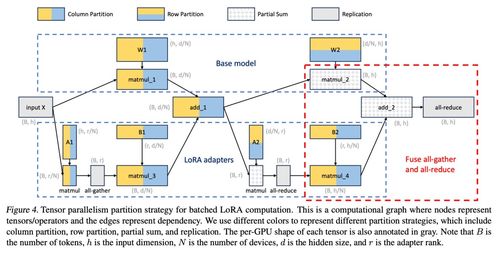
- 定制化CUDA内核与高效计算:为了高效处理来自不同适配器的并发前向与反向传播请求,研究团队开发了高度优化的定制化CUDA内核。这些内核能够将批处理中涉及不同基础模型和不同适配器的计算进行有效整合,最大化GPU计算单元的利用率,避免了因频繁切换模型而导致的巨大开销。
- 层级化存储与数据编排:在数据处理和存储方面,S-LoRA引入了一套层级化、结构化的存储方案。它将基础模型权重、共享的LoRA投影矩阵以及成千上万个任务特定的适配器权重进行分离存储和高效索引。通过精心设计的数据布局和读取策略,确保了在需要时能够以极低的延迟获取到正确的参数,从而支持高并发的模型服务。
三、 技术突破与显著优势
实验结果表明,S-LoRA实现了质的飞跃:
- 惊人的扩展能力:在单个A100 GPU上,S-LoRA成功实现了同时服务超过2000个LoRA微调模型(例如,基于Llama 2 70B这样的大模型),而传统方法在服务几十个后就会因显存不足而崩溃。
- 极低的额外开销:相较于服务单一模型,S-LoRA在服务大量模型时引入的额外延迟和吞吐量下降微乎其微,保持了高推理效率。
- 无缝兼容与易用性:S-LoRA与现有的Transformer架构和LoRA微调范式完全兼容,开发者可以沿用熟悉的训练流程获得适配器,然后轻松集成到S-LoRA服务框架中。
四、 应用前景与行业影响
S-LoRA的提出具有深远的意义:
- 大规模个性化AI服务:使得为海量用户提供独一无二的、经过个人数据或领域知识微调的AI助手成为可能,例如教育、客服、创意写作等领域的深度定制。
- 高效多租户模型部署:云服务商可以在同一套硬件基础设施上,以极低的边际成本为成千上万的客户托管其专属的微调模型。
- 推动AI民主化:大幅降低了使用和部署定制化大模型的技术门槛与经济成本,使更多研究机构、中小企业乃至个人开发者能够受益于大模型的能力。
- 研究新范式:它为持续学习、终身学习以及基于大量任务的高效元学习提供了强有力的系统支持。
五、 与展望
UC伯克利团队的S-LoRA工作,不仅仅是一项具体的算法改进,更是一次从系统层面重新思考大模型微调与部署范式的成功实践。它巧妙地将算法(LoRA)与系统工程(内存管理、内核优化、存储编排)相结合,破解了规模化个性AI的核心瓶颈。随着技术的进一步完善和开源(相关代码已发布),S-LoRA有望成为未来大模型应用生态中的一项基础性技术,加速人工智能向更智能、更个性化、更普惠的方向发展,真正让“千人千模”从愿景走向现实。
最新产品