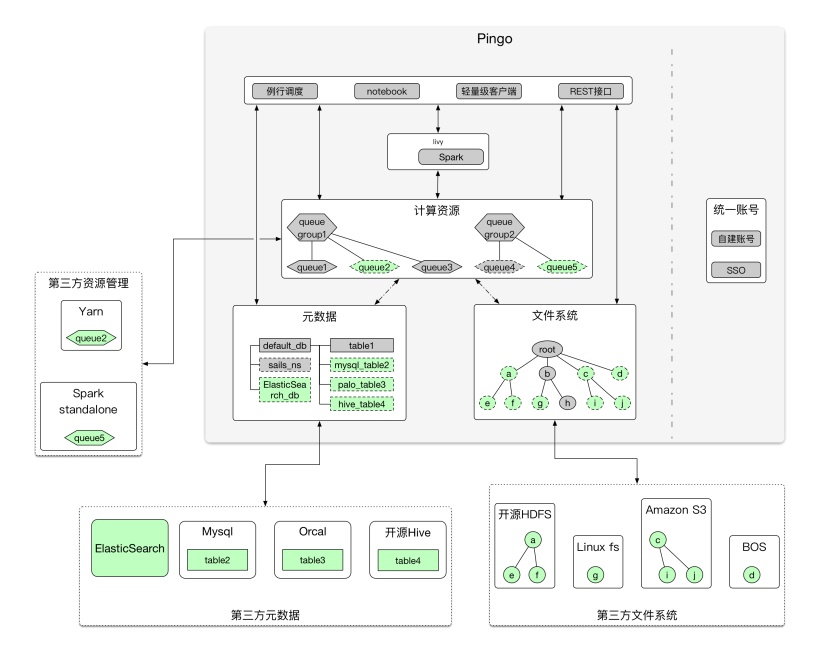
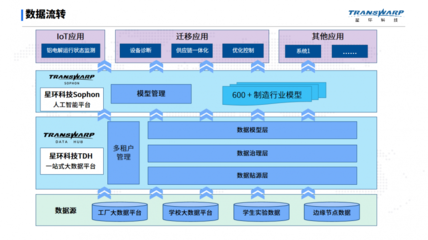
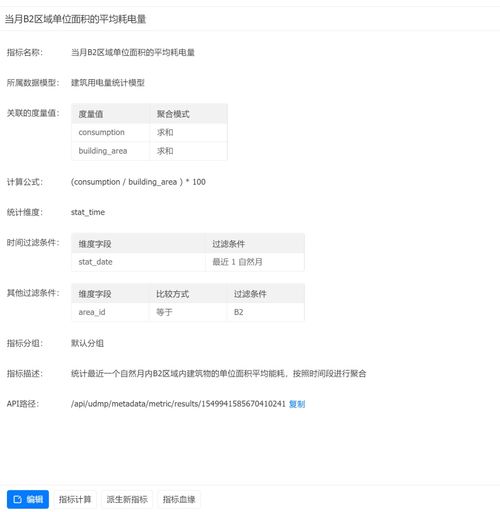
大数据的14个基础概念,用大白话教你搞懂数据处理与存储
在数字化时代,“大数据”早已不是陌生词汇,但真正理解其核心概念却并不容易。今天,我们就用最通俗的语言,为你拆解大数据的14个基础概念,让你轻松搞明白数据处理与存储的那些事儿。
1. 大数据(Big Data)
简单说,就是海量到传统工具难以处理的数据。特点是“4V”:量大(Volume)、类型多(Variety)、速度快(Velocity)、价值密度低(Value)。
2. 结构化数据(Structured Data)
像Excel表格那样,规规矩矩、有固定格式的数据,比如数据库里的信息。
3. 非结构化数据(Unstructured Data)
没固定格式的数据,比如图片、视频、社交媒体帖子、邮件内容。
4. 半结构化数据(Semi-structured Data)
介于两者之间,有一定结构但不严格,比如JSON、XML格式的数据。
5. 数据仓库(Data Warehouse)
可以理解成公司的“数据图书馆”,专门存储清洗过、整理好的历史数据,用于分析和决策。
6. 数据湖(Data Lake)
像一个大水库,原始数据(不管有没有清洗)都往里扔,需要时再提取分析,更灵活。
7. ETL(提取、转换、加载)
数据处理三步曲:从不同地方“提取”数据,“转换”成统一格式,“加载”到数据仓库或湖中。
8. 批处理(Batch Processing)
不着急,攒一波数据再一起处理,比如每晚统计当日销售额。
9. 流处理(Stream Processing)
数据像水流一样实时涌来,立刻处理,比如实时监控交通路况或电商促销时的交易数据。
10. 分布式存储(Distributed Storage)
数据不放在一台机器上,而是分散到多台电脑(节点)存储,更安全、扩展性更强。
11. NoSQL数据库(Not Only SQL)
不局限于传统表格形式的数据库,更适合处理非结构化或半结构化的大数据,比如文档型、键值对型数据库。
12. Hadoop
一个开源的大数据处理“工具箱”,核心是HDFS(分布式文件系统)和MapReduce(并行计算框架)。
13. Spark
比Hadoop MapReduce更快的数据处理引擎,擅长内存计算,适合迭代式和实时分析。
14. 数据挖掘(Data Mining)
从大量数据里“挖”出隐藏的模式、趋势和知识,比如预测用户行为、发现商业机会。
掌握这些概念,你就有了理解大数据世界的基础地图。数据处理与存储的核心,其实就是如何高效地“收、存、算、用”海量信息,让数据真正为业务创造价值。从数据仓库到数据湖,从批处理到流处理,技术不断演进,但目标始终如一:让数据说话,让决策更聪明。
最新产品