《大数据技术原理与应用》第七章 MapReduce——数据处理与存储的核心引擎
林子雨教授的《大数据技术原理与应用》第七章,深入剖析了大数据处理领域具有里程碑意义的计算模型——MapReduce。本章不仅阐述了其基本概念,更系统性地揭示了其在数据处理与存储任务中的核心作用与实现原理。
一、核心概念:分而治之的哲学
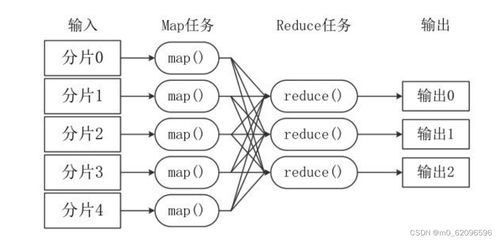
MapReduce的设计灵感源于函数式编程中的map(映射)和reduce(归约)操作,其核心思想是“分而治之”。它将复杂的大规模数据集处理任务,分解为两个主要阶段:
- Map阶段:由多个
Map任务并行执行。每个任务读取输入数据的一个分片,对其进行处理,并输出一系列的中间键值对(<key, value>)。此阶段的核心是“分散”,将计算推向数据所在的节点,避免大规模数据移动。 - Reduce阶段:由多个
Reduce任务并行执行。框架会将Map阶段输出的所有中间键值对,按照key进行排序和分组(Shuffle过程),将相同key的数据发送到同一个Reduce任务。Reduce任务对接收到的、属于同一key的value列表进行归约计算,并最终输出结果。此阶段的核心是“汇总”。
这种模型将并行计算、数据分发、容错管理等复杂细节封装在框架内部,使开发者只需关注Map和Reduce两个核心逻辑函数的实现,极大简化了分布式程序的开发。
二、数据处理:从原始数据到有价值信息
在数据处理层面,MapReduce展现出了强大的能力:
- 结构化与非结构化数据处理:无论是日志文件、网页文档还是数据库记录,MapReduce都能通过自定义的
Map函数进行解析和提取。 - 复杂计算模式的实现:通过精心设计键值对,MapReduce可以实现过滤、排序、聚合(如求和、计数、平均值)、连接(Join)乃至更复杂的迭代计算(如图处理)。
- Shuffle与排序的枢纽作用:这是连接Map和Reduce的“心脏”。系统自动完成的排序和分组,是保证Reduce阶段能够正确进行归约的基础,也是性能优化的关键点之一。
三、数据存储:与HDFS的深度集成
MapReduce的数据存储与处理紧密依托于Hadoop分布式文件系统(HDFS),这构成了经典的Hadoop1.0核心(HDFS + MapReduce)。
- 数据本地化优化:MapReduce调度器会尽可能将
Map任务调度到存储其所需数据块的HDFS数据节点上执行,实现了“计算向数据迁移”,显著减少了网络传输开销。 - HDFS作为输入/输出源:MapReduce的输入数据通常直接来自HDFS,处理后的结果也写回HDFS进行持久化存储。HDFS的高可靠性和高吞吐量特性,为MapReduce处理海量数据提供了坚实的存储基础。
- 中间结果的存储:Map阶段产生的中间结果会先写入本地磁盘,而非HDFS。Reduce任务通过HTTP拉取这些中间数据。这种设计权衡了可靠性与I/O效率。
四、典型应用场景
MapReduce模型适用于批量处理大规模数据,其经典应用包括:
- 词频统计:最经典的入门案例,完美展示了Map(分词并输出
<单词, 1>)和Reduce(对同一单词的计数列表求和)的过程。 - 网页索引与倒排索引构建:搜索引擎的核心预处理步骤。
- 日志分析与数据挖掘:分析用户行为、系统运行状态,如统计PV/UV、发现异常模式。
- 机器学习算法:一些可并行化的算法,如朴素贝叶斯分类、协同过滤推荐等,均可通过MapReduce实现分布式训练。
五、局限性与演进
尽管MapReduce曾是大数据处理的代名词,但其自身也存在局限性,如:
- 实时性差:基于磁盘I/O的批处理模型,延迟通常在分钟甚至小时级。
- 编程模型不够灵活:复杂任务(如多迭代、有向无环图)需要串联多个MapReduce作业,开发复杂且效率较低。
- 资源管理耦合:在Hadoop1.0中,MapReduce框架同时负责作业调度和资源管理,扩展性受限。
这些局限催生了大数据计算框架的演进:资源管理与作业调度被抽象为独立的YARN(Hadoop2.0核心),而更灵活、高效的计算模型如Spark(基于内存的DAG计算)、Flink(流批一体)等逐渐成为新的主流。MapReduce所确立的分布式、容错、数据并行的思想,至今仍是整个大数据处理体系的基石。
###
第七章的MapReduce,不仅仅是一项具体技术,更代表了一种处理海量数据的经典范式。它深刻体现了将大规模计算任务自动化分解、调度、执行并管理故障的智慧。理解MapReduce的原理,是理解现代分布式计算框架演进脉络的起点,对于掌握大数据技术的核心思想至关重要。尽管其直接使用率在下降,但其设计哲学与核心概念已内化于后续更高级的系统中,持续发挥着影响力。
最新产品