开源实时数据处理系统Pulsar 一站式融合Kafka、Flink与数据库功能的数据处理与存储解决方案
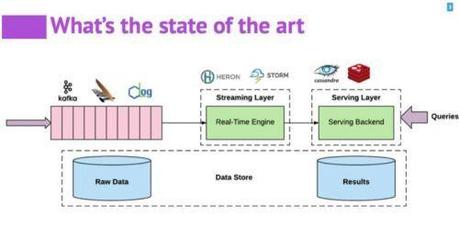
随着大数据和实时计算需求的爆炸式增长,企业面临着数据处理流水线复杂、技术栈冗余和维护成本高昂的挑战。传统的解决方案往往需要组合多个系统:例如使用Kafka进行消息队列,Flink进行流式计算,再依赖各类数据库进行状态存储与查询。这种组合虽然功能强大,但也带来了架构复杂、运维困难和数据一致性等问题。在此背景下,Apache Pulsar作为新一代的云原生分布式消息流平台,正以其独特的设计理念,朝着“一套系统搞定Kafka+Flink+DB”的愿景迈进,为实时数据处理与存储提供了一站式解决方案。
一、Pulsar的核心优势:统一的消息、存储与计算层
Pulsar的设计哲学是构建一个统一的数据层。它原生融合了传统消息队列、流存储和轻量级计算的能力。
- 超越Kafka的消息与流存储能力:Pulsar采用分层架构(计算与存储分离),Broker负责计算和调度,BookKeeper集群提供持久化存储。这使得它具备比Kafka更灵活的扩缩容能力、更高效的地理复制机制以及无限的主题分区扩展性。其多租户、命名空间和细粒度权限控制特性,使其天生适合云原生和多团队协作环境。
- 内置的流处理引擎:Pulsar Functions:Pulsar集成了轻量级计算框架Pulsar Functions,允许用户以简单的函数形式在数据流经时进行实时处理,如过滤、转换、聚合等。这类似于一个简化版的、无需复杂部署的Flink作业,特别适用于ETL、实时事件响应等场景,降低了流处理入门门槛。
- 一体化的分层存储与数据库式访问:Pulsar支持将老旧数据自动卸载到更廉价的存储系统(如S3、HDFS),同时保持对数据的透明访问。更重要的是,通过Pulsar SQL(基于Presto)功能,用户可以直接使用标准SQL语句查询存储在Pulsar中的历史数据和实时数据流,实现了类似数据库的即时查询体验,模糊了消息队列与数据库的边界。
二、如何实现“一套搞定”?
Pulsar通过其扩展组件和生态,正在构建一个闭环的实时数据平台:
- 数据摄入与分发(替代部分Kafka角色):作为高性能的Pub-Sub消息系统,Pulsar完美承接了从各种数据源实时接入数据,并分发给下游消费者的任务,其性能、可靠性和特性集已得到广泛验证。
- 实时计算与转换(替代部分Flink角色):对于复杂度中等的流处理任务,Pulsar Functions和更强大的Pulsar Flink Connector提供了深度集成。用户可以利用Flink强大的计算模型处理Pulsar中的数据,同时享受Pulsar带来的弹性优势。Pulsar在此场景下扮演了完美的流存储角色,与Flink形成了“存储与计算分离”的最佳实践。
- 状态存储与查询(替代部分DB角色):通过分层存储和Pulsar SQL,Pulsar使得长期存储和查询海量流数据成为可能。对于需要实时查询最新状态的场景,可以结合TableView等API,或将处理后的结果流直接写入Pulsar主题,并通过SQL查询,构建出实时的状态视图。
三、典型应用场景与架构
设想一个实时风控系统:
- 交易日志通过SDK直接写入Pulsar主题。
- 一个Pulsar Function实时过滤出高风险交易特征事件。
- 复杂的风控规则模型(如机器学习模型评分)通过Flink作业从Pulsar读取数据,进行处理,并将风险评分结果写回另一个Pulsar主题。
- 所有的原始交易日志和风险评分结果都持久化在Pulsar中,并自动分层存储。
- 风控分析师可以通过Pulsar SQL直接对联机或归档的历史交易数据进行即席查询和分析,无需数据搬迁。
在这个架构中,Pulsar同时承担了数据管道(Kafka角色)、轻量计算(部分Flink角色)和可查询存储(DB角色)的职责,极大简化了技术栈。
四、挑战与考量
尽管前景广阔,但完全用Pulsar“一套搞定”仍需理性看待:
- 成熟度与生态:Kafka和Flink拥有更悠久的历史和更庞大的生态系统。对于极度复杂的状态流处理,Flink目前可能仍是更成熟的选择。
- 运维复杂度:Pulsar的架构本身涉及多个组件(Broker, Bookie, ZooKeeper),部署和运维的初始复杂度高于Kafka,但其云原生设计在长期运维中可能更具优势。
- 技术选型:并非所有场景都需要“大而全”的方案。对于简单的日志传输,Kafka可能更轻量;对于复杂的批流一体处理,Flink+数据湖的方案可能更合适。
###
Apache Pulsar并非意在简单地替代Kafka、Flink或数据库,而是通过创新的架构,旨在提供一个统一的、简化的大数据基础层。它将消息传递、流存储和实时处理的能力紧密集成,使开发人员能够更专注于业务逻辑,而非在多个系统间进行繁琐的集成、运维和数据搬运。对于正在构建新一代实时数据平台的企业而言,Pulsar提供了一个极具吸引力的、面向未来的“一站式”选项,正逐步将“一套系统融合多种能力”的梦想变为现实。
最新产品
探秘数据工厂Pingo的多存储后端数据联合查询技术
打破产教边界 TDH+Sophon赋能,山东某高校打造“课堂即工厂”数字化转型实训平台
多子系统多业务模块的复杂数据处理 基于指令集物联网操作系统的项目开发实践
事务处理不当,线上接口又双叒内存泄漏了 从数据处理到存储的代码视角
工厂数据混乱怎么办?MES系统替你解决数据收集与存储难题
水处理从业人员必看 26个工业废水处理工艺流程图数据管理与应用
Azure入门(三) 选择合适的数据存储服务与数据处理和存储务
Seata分布式事务实践与开源详解 数据处理和存储务

存储邂逅AI 雷克沙创新存储解决方案亮相COMPUTEX 2025
人工智能赋能芯片制造 数据处理与存储的全新范式