MySQL数据库核心特性 索引、事务与存储引擎的数据处理与存储实务
在数据驱动的现代应用中,MySQL作为一款广泛使用的关系型数据库管理系统,其核心特性——索引、事务与存储引擎——是保障数据高效处理与安全存储的基石。深入理解并合理运用这些特性,对于构建高性能、高可用的数据服务至关重要。本文将从数据处理与存储的实际业务场景出发,探讨这三者的原理、关联与实践。
一、 索引:加速数据检索的利器
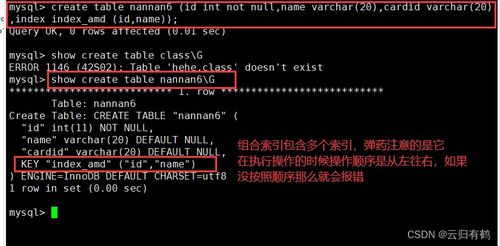
索引是数据库中的一种数据结构,类似于书籍的目录,其核心目的是加快数据的查询速度。通过在表的一个或多个列上创建索引,数据库可以避免全表扫描,快速定位到所需的数据行。
- 工作原理:常见的索引类型如B+Tree索引,它将数据有序地组织起来,使得范围查找、排序和分组操作非常高效。当执行查询时,优化器会评估是否使用索引以及使用哪个索引。
- 实务要点:
- 创建策略:为频繁出现在
WHERE、JOIN、ORDER BY和GROUP BY子句中的列创建索引。
- 权衡代价:索引会占用额外的磁盘空间,并会在数据插入、更新和删除时带来维护开销,因为索引结构也需要同步更新。因此,并非索引越多越好。
- 索引选择:理解不同索引类型(如唯一索引、复合索引、全文索引)的适用场景。例如,复合索引遵循最左前缀匹配原则。
二、 事务:保障数据一致性的单元
事务是数据库操作的最小逻辑工作单元,它确保了一系列的数据库操作要么全部成功,要么全部失败,以此维护数据的完整性与一致性。这通过ACID特性来保证:
- ACID特性:
- 原子性 (Atomicity):事务是不可分割的整体。
- 一致性 (Consistency):事务使数据库从一个一致状态转变到另一个一致状态。
- 隔离性 (Isolation):并发执行的事务彼此隔离,互不干扰。
- 持久性 (Durability):事务提交后,其对数据的修改是永久性的。
- 实务要点:
- 隔离级别:MySQL提供了读未提交、读已提交、可重复读(默认级别)和串行化四个隔离级别。级别越高,一致性越强,但并发性能可能越低。需要根据业务对脏读、不可重复读、幻读的容忍度来选择。
- 事务控制:显式地使用
BEGIN、COMMIT和ROLLBACK语句来控制事务边界。对于复杂的业务逻辑,合理设计事务的范围(避免长事务)是关键。
三、 存储引擎:数据存储与管理的底层架构
存储引擎是MySQL中负责数据的物理存储、索引实现和事务支持的底层组件。MySQL支持多种存储引擎,最常用的是InnoDB和MyISAM。
- 核心引擎对比:
- InnoDB:
- 支持事务,具备完整的ACID特性,是MySQL 5.5及以后版本的默认引擎。
- 支持行级锁和外键约束,更适合高并发、要求数据一致性的OLTP(在线事务处理)应用。
- 使用聚集索引,数据文件本身即索引文件的一部分。
- MyISAM:
- 不支持事务和外键。
- 表级锁,在读写混合的并发场景下性能受限。
- 读取速度非常快,适用于以读为主、对事务要求不高的OLAP(在线分析处理)或静态数据存储场景。
- 实务要点:
- 引擎选择:在创建表时(
CREATE TABLE ... ENGINE=...)指定。现代绝大多数业务场景应首选InnoDB,除非有明确的只读、全文索引(MyISAM有特殊的全文索引实现)等特殊需求。
- 配置优化:不同的存储引擎有各自的关键配置参数。例如,对InnoDB,需要合理设置
innodb<em>buffer</em>pool_size(缓冲池大小)来提升性能。
四、 协同工作:数据处理与存储的综合实务
在实际业务中,索引、事务和存储引擎并非孤立存在,而是协同工作以完成高效、可靠的数据处理。
- 场景示例:一个电商下单流程。
- 存储引擎:使用InnoDB,因为它需要支持事务(确保扣减库存、生成订单、更新账户余额等操作的一致性)和高并发。
- 事务:将扣减库存、创建订单记录、记录支付流水等操作包裹在一个事务中。这保证了即使中间步骤失败,所有更改也能回滚,避免数据不一致(如库存扣了但订单没生成)。
- 索引:在商品表的商品ID和库存字段上建立索引,可以快速定位并锁定(通过InnoDB的行锁)要购买的商品记录,加速库存检查与扣减操作。在订单表的用户ID和创建时间上建立索引,方便用户快速查询历史订单。
###
掌握MySQL的索引、事务与存储引擎,是进行有效数据库设计与优化的核心。正确的索引策略是性能的保障,合理的事务控制是数据安全的防线,而合适的存储引擎选择则是这一切的基石。在实际开发与运维中,应根据具体的业务负载、数据一致性要求和并发场景,综合运用这三者,才能构建出既稳健又高效的数据存储与处理系统。
最新产品
兆芯与火星高科强强联手,推出创新存储与服务器解决方案
存算并举,前店后厂 华为递出数据要素时代的践行答卷
数据库需求分析中的数据处理与存储任务
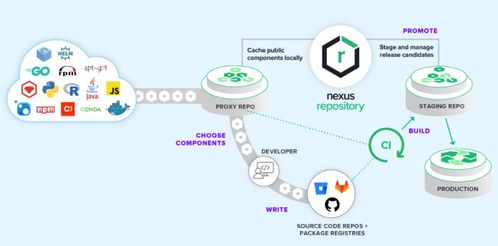
DevOps制品管理 超越存储,迈向数据处理与智能化的核心枢纽
大数据的14个基础概念,用大白话教你搞懂数据处理与存储

数据处理与存储安全 驱动网络安全产业迈向2500亿规模新纪元
元力股份以4500万元转让广州原力100%股权,全面剥离网游资产聚焦数据处理与存储主业
全新版本MongoDB 为物联网数据处理与存储注入强劲动力
自行搭建威胁感知大脑SIEM 数据处理与存储实践
开源实时数据处理系统Pulsar 一站式融合Kafka、Flink与数据库功能的数据处理与存储解决方案