Spark数据读取、处理与保存 高效数据处理与存储实践
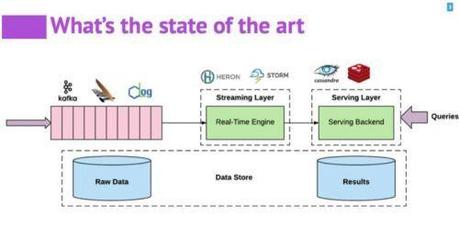
Apache Spark作为现代大数据处理的核心框架之一,以其卓越的性能和易用性,在数据工程和分析领域占据重要地位。本文将系统性地介绍Spark中数据读取、处理与保存的全流程,并探讨确保数据处理与存储高效可靠的最佳实践。
一、数据读取:多样化的数据源支持
Spark提供了丰富的数据源接口,支持从多种存储系统中读取数据。
1. 结构化数据读取:
- Spark SQL与DataFrame API:通过spark.read方法,可以轻松读取CSV、JSON、Parquet、ORC、Avro等格式的文件。例如:
`scala
val df = spark.read.format("csv").option("header", "true").load("/path/to/data.csv")
`
- JDBC数据源:可直接从关系型数据库(如MySQL、PostgreSQL)中读取数据,便于与现有数据仓库集成。
- 非结构化与半结构化数据:
- 文本文件:使用
textFile方法读取纯文本文件,每行作为一条记录。
- Hadoop输入格式:支持SequenceFile等Hadoop原生格式。
- 流式数据读取:通过Spark Structured Streaming,可以从Kafka、文件系统等数据源实时读取流数据。
最佳实践:
- 根据数据特性和处理需求选择合适的数据格式(如列式存储的Parquet适合分析型查询)。
- 利用schema选项显式定义数据结构,避免Schema推断开销并提高准确性。
- 对于大规模数据,合理配置分区和并行度以优化读取性能。
二、数据处理:核心转换与操作
数据读取后,Spark提供了强大的转换和操作能力。
- DataFrame/Dataset API:
- 转换操作:包括
select、filter、groupBy、agg、join等,支持类似SQL的声明式编程。
- 行动操作:如
count、show、collect,触发实际计算并返回结果。
- Spark SQL:
- 通过
spark.sql()执行标准SQL查询,简化复杂的数据处理逻辑。
- 注册临时视图后,即可用SQL进行交互式分析。
- 高级处理:
- 窗口函数:支持复杂的分组聚合和排序操作。
- UDF(用户自定义函数):扩展处理能力以应对特定业务逻辑。
- 机器学习与图计算:集成MLlib和GraphX库,支持更高级的数据分析。
最佳实践:
- 尽量使用DataFrame API而非低级的RDD API,以利用Catalyst优化器和Tungsten执行引擎的性能优势。
- 避免在转换操作中使用collect将数据拉取到Driver端,以防内存溢出。
- 合理使用缓存(persist或cache)来复用中间结果,尤其适用于迭代算法和多步骤处理。
三、数据保存:持久化处理结果
处理完成后,需要将结果保存到持久化存储中。
- 文件格式保存:
- 使用
df.write.format("parquet").save("/output/path")将数据保存为特定格式。
- 支持分区保存,便于后续查询优化:
`scala
df.write.partitionBy("date", "category").parquet("/output/path")
`
- 数据库写入:
- 通过JDBC将结果写回关系型数据库。
- 支持覆盖(overwrite)、追加(append)等保存模式。
- 流式输出:
- Structured Streaming支持将流处理结果输出到文件、数据库或控制台。
最佳实践:
- 根据数据使用场景选择存储格式:分析型查询优选Parquet,频繁更新可考虑Delta Lake等事务性格式。
- 利用分区和分桶(bucketing)优化存储布局,提升后续查询性能。
- 对于关键数据,考虑启用压缩(如Snappy、GZIP)以节省存储空间,但需权衡CPU开销。
- 实施数据版本控制和生命周期管理,结合HDFS快照或云存储版本功能。
四、端到端数据处理与存储考量
- 性能调优:
- 合理设置
spark.sql.shuffle.partitions等参数,优化Shuffle阶段性能。
- 监控Executor内存使用,避免GC(垃圾回收)开销过大。
- 容错与一致性:
- Spark的RDD血统(lineage)机制提供天然容错。
- 对于关键作业,可启用检查点(checkpointing)以切断过长血统链。
- 在分布式环境下,注意数据一致性,尤其是流处理中的Exactly-Once语义保障。
- 资源管理:
- 根据集群资源情况动态分配Executor和核心数。
- 利用动态分配(Dynamic Allocation)提高资源利用率。
- 数据安全与治理:
- 集成Kerberos等认证机制,实施基于角色的访问控制(RBAC)。
- 对敏感数据实施加密(静态加密和传输加密)。
- 记录数据血缘关系,便于审计和问题追踪。
###
Spark数据读取、处理与保存构成了大数据处理的核心闭环。通过熟练掌握Spark API、合理选择存储格式、实施性能优化与容错机制,可以构建高效、可靠的数据流水线。随着数据规模的增长和业务复杂度的提升,持续关注Spark社区的新特性(如Adaptive Query Execution、Delta Lake集成)并将其融入现有架构,将有助于保持数据处理平台的先进性和竞争力。一个优秀的数据处理系统不仅需要强大的技术支撑,更离不开对业务需求的深刻理解与灵活适配。
最新产品